In Part A of the project, I loaded the pretrained checkpoints of the DeepFloyd IF diffusion model and implemented unconditional
& conditional sampling loops. Then, I implemented various methods to edit images with the diffusion model, including revisiting image synthesis and creating images that, when flipped, looks like something different.
For Part B, I reimplemented diffusion models with a U-Net backbone and trained it on the MNIST toy dataset.
Setup
After loading the 2 stages of the pretrained DeepFloyd IF diffusion model, I try the official implementation of sampling. I try 5, 20, and 100 sampling steps, and the more steps we sample, the better quality the generated images are. The images captures the object described in the prompts. The three sets of images are shown below, generated with the random seed 100.
The Forward Process
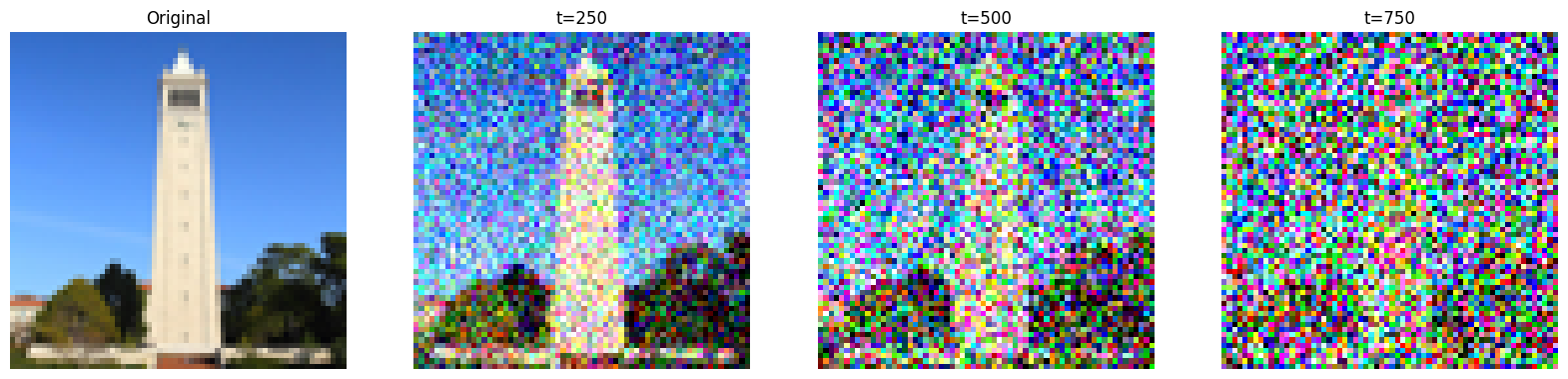
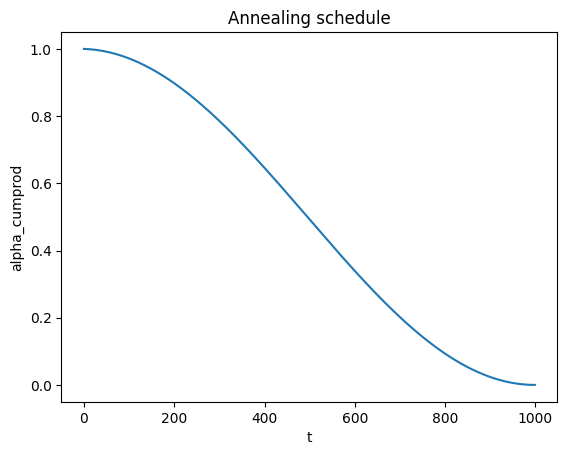
Given an annealing schedule of \(\bar{\alpha}_t\), the forward process at timestep \(t\) perturbs the original image \(x_0\) as \(x_t = \sqrt{\bar{\alpha}_t} x_0 + \sqrt{1 - \bar{\alpha}_t} \epsilon \) where \(\epsilon \sim \mathcal{N}(0, I)\). The original image we use is a photo of the Campanile and the forward process is shown below. The annealing schedule is also shown below.
Classical Denoising
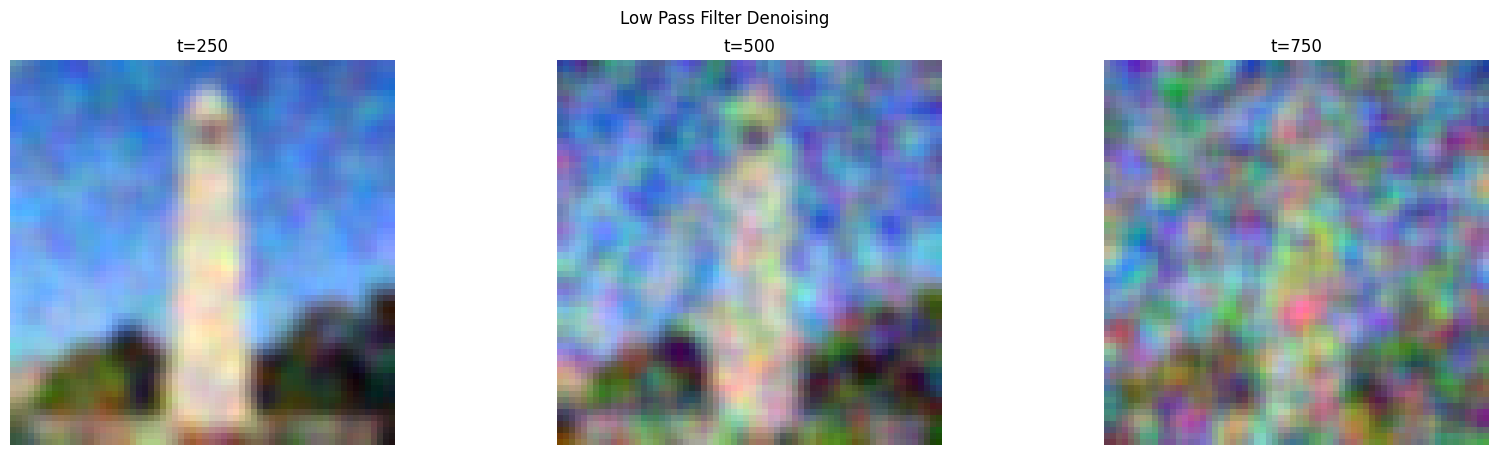
As a naive baseline, I use the Gaussian filter with kernel width 5 and sigma 2 and low pass filter the image. The results of denoising the perturbed images in the previous part are shown below. We see that the Gaussian filter does not really remove the noise, especially for the high noise levels.
One-Step Denoising
As a slightly less naive baseline, we can use one-step denoising by leveraging the stage 1 model of the DeepFloyd IF diffusion model. Since the model is predicting noise, we can simply call the model once, and subtract the predicted noise from the perturbed image. The results of denoising the perturbed images in the previous part are shown below. We see that the one-step denoising does a much better job than the Gaussian filter, bug for the high noise levels the image is still blurry.
Iterative Denoising
Instead, we can use iterative denoising to produce a better quality image. Assume we have two timesteps \(t' < t\), from the perturbation process we know that \(x_{t'} = \frac{\sqrt{\bar{\alpha}_{t'}} \beta_t}{1 - \bar{\alpha}_t} x_0 + \frac{\sqrt{\alpha_t} (1 - \bar{\alpha}_{t'})}{1 - \bar{\alpha}_t} x_t + v_{\sigma}\), where \(\alpha_t = \frac{\bar{\alpha}_t}{\bar{\alpha}_{t'}}, \beta_t = 1 - \alpha_t\), and \(v_{\sigma}\) is the random noise. We want to go from more noisy image to less noisy image (i.e., from \(x_t\) to \(x_{t'}\)), but we don't know the noise \(v_{\sigma}\) and the ground truth \(x_0\). Fortunately, the DeepFloyd IF diffusion model can help us estimate the noise, so we can estimate \(\hat{x}_0\) by subtracting the predicted noise from \(x_t\). The model also gives an estimate for the variance, and we can use that to construct \(v_{\sigma}\). The process of iterative denoising an image perturbed at timestep 690 is shown below.
Below, I compare the results of iterative denoising with the one-step denoising and low pass filter denoising. We see that iterative denoising produces the best results.
Diffusion Model Sampling
We have been motivating diffusion models with denoising. However, we can also sample completely new images by feeding in a gaussian white noise and run iterative denoising on the diffusion model. With a prompt "a high quality photo", we can generate the following images. We can see the althouth we are conditioning on the langauge input, the generated images are still not very good. We will fix this with Classifier-Free Guidance in the next part.
Classifier-Free Guidance (CFG)
Conditioning on a dummy language input (e.g., an empty string) and an actual language input (e.g., "a high quality photo" in this part and more meaningful prompts in the following parts), the diffusion model outputs an unconditional noise prediction \(\epsilon_u\) and a conditional noise prediction \(\epsilon_c\). We use \(\epsilon_u + \gamma \cdot (\epsilon_c - \epsilon_u)\) as our overall noise estimate. The trick for generating high quality images that is consistent with our prompt is to set \(\gamma > 1\). Here we set it to be 7. Five samples generated through CFG are shown below. We see that the generated images are much better than the unconditional sampling.
Image-to-image Translation
We can think of the denoising process as projecting a noisy image onto the manifold of clean images. The SDEdit altorithm perturbs a given images a bit and use diffusion to project it back to the space of realistic images. Below are some examples.
We can also use fictional images as inputs to SDEdit. However, the generated images are biased towards human, and after multiple tries I still cannot get a good image of a house.
Alternatively, we can force parts of the generated image to be belong to a true image, and only inpaint a section specified through a mask. Three examples are shown below. The gray overtone is because we normalized the image before feeding it into the diffusion model.
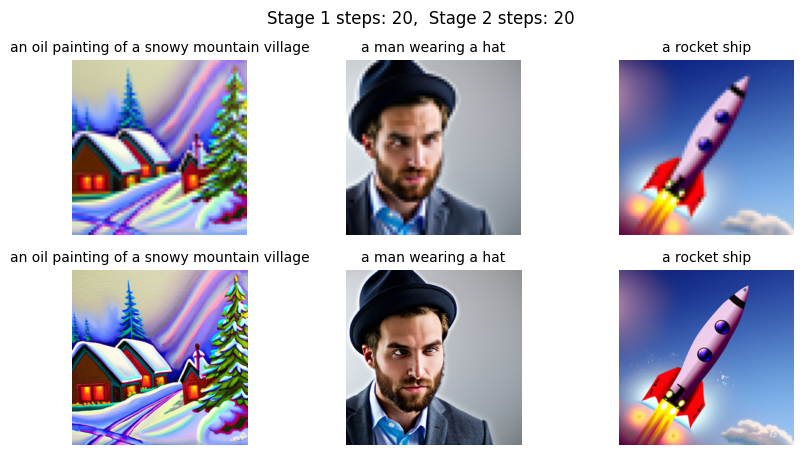
If we provide language prompts to guide the projection process, we can achieve text-conditional image-to-image translation.
Prompt: "a rocket ship" Prompt: "an oil painting of people around a campfire" Prompt: "a man wearing a hat"
Visual Anagrams
By flipping the noise estimate from two language prompts and averaging them together, we can generate images that, when flipped, looks like something different. Below are three examples.
Hybrid Images
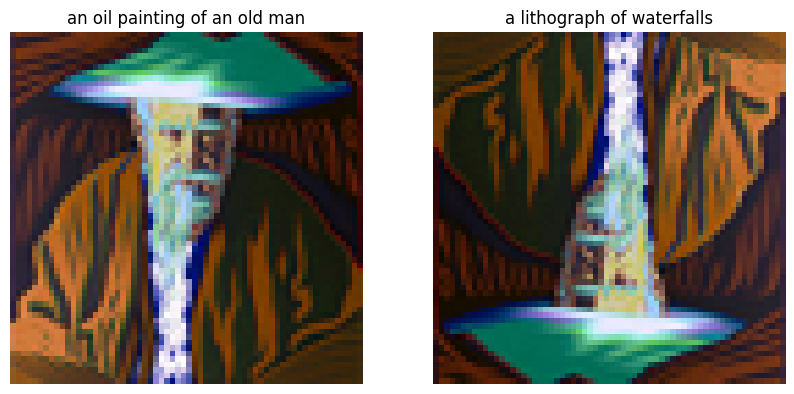
Finally, by low pass filtering and high pass filtering the predicted noises for two language prompts and adding them together, we can generate hybrid images. Below are three examples.
Hybrid image of a skull and a waterfallHybrid image of an old man and a snowy mountain villageHybrid image of a man wearing a hat and the amalfi cost
Training a Single-Step Denoising UNet
In the following sections we train a denoising UNet on the MNIST dataset. Specifically, we perturb the image with \(z = x + \sigma \epsilon, \epsilon \sim \mathcal{N}(0, I)\). The perturbation process is shown below.
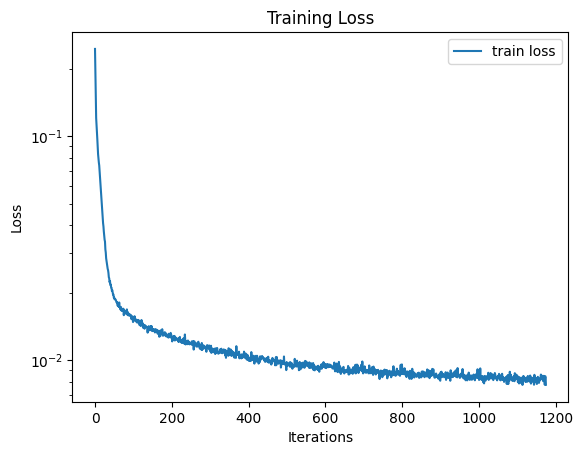
During training, we fix the noise level \(\sigma = 0.5\) and the model \(D_\theta\) is trained to directly predict the denoised image, i.e., minimizing the loss \(\mathbb{E}_{z, x}[\lVert D_\theta(z) - x \rVert^2]\). The UNet with 128 hidden dimensions is trained for 5 epochs with batch size 256 using the Adam optimizer with lr 0.0001, and the loss curve is shown below.
At the end of the first epoch, the denoising effect on the test set is shown below.
The denoising effect on the test set at the end of the fifth epoch is shown below. We see that the denoising effect is better than the model trained only on one epoch.
One drawback of the training scheme is that, as a one-step method, we must know the noise level a priori. The denoising effect of the fully trained model on different levels of noises are shown below (it is considered out of distribution). Note that the model performs poorly on large noise levels.
Adding Time Conditioning to UNet
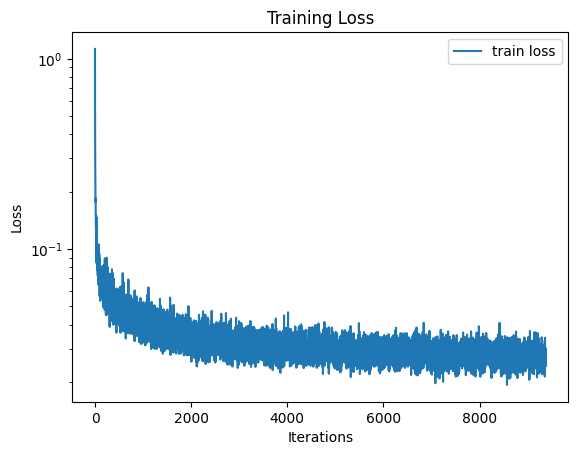
We can improve the diffusion model by conditioning on the timestep, e.g., the amount of noise. With the UNet conditioned on the timestep, the training objective becomes minimizing the loss \(\mathbb{E}_{z, x, t}[\lVert \epsilon_\theta(z, t) - \epsilon \rVert^2]\) with \(z = \sqrt{\bar{\alpha}_t} x + \sqrt{1 - \bar{\alpha}_t} \epsilon, \epsilon \sim \mathcal{N}(0, I)\). The UNet with 64 hidden dimensions is trained for 20 epochs with batch size 128 using the Adam optimizer with initial lr 0.001 and exponential lr decay (coefficient is 0.9), and the loss curve is shown below.
Below are the samples generated by the UNet through iterative denoising at the end of the fifth and twentieth epochs. We see that the denoising effect is better at the end of the twentieth epoch. Since we are not conditioning on the classes, we cannot control the digit that we generate. Note that the gif should count as bells and whistles.
Sampling GIF at Epoch 5Sampling GIF at Epoch 20
Adding Class-Conditioning to UNet
Finally, since in MNIST we have 10 classes, we would like to control which digit we generate. We can do this by adding class conditioning to the UNet architecture. The training setup is identical to the previous part. The training loss curve is shown below.
Below are the samples generated by the UNet through iterative denoising at the end of the fifth and twentieth epochs. We see that the denoising effect is better at the end of the twentieth epoch. Since we can condition on the class, we can control which digit to generate. The quality of the generated images are also better than the time-conditioned model.